OnlineOrNot's lessons from Cloudflare's outage on 2025-11-18

Max Rozen / Published: November 19, 2025
On 2025-11-18 at 11:48 UTC, Cloudflare declared an incident affecting the global network (that also affected OnlineOrNot). OnlineOrNot monitors websites, APIs, web apps, and cron jobs, while providing status pages as well.
While we partially mitigated the issue by enabling a fallback to AWS-based monitoring, between 13:00 UTC and 14:33 UTC failing checks went unreported, heartbeat checks over-reported, and status pages were unavailable. This postmortem outlines what went wrong, and what will be done to fix the issues.
Table of contents:
- OnlineOrNot's dashboard and public API
- OnlineOrNot's uptime checking system
- OnlineOrNot's heartbeat (cron) monitoring system
- OnlineOrNot's status pages
- Remediation steps
OnlineOrNot's dashboard and public API
OnlineOrNot's frontend (onlineornot.com) is currently deployed in a single place: AWS Lambda (through Vercel) in us-east-1, with the DNS proxied on Cloudflare. The public API on the other hand, runs purely on Cloudflare Workers.
OnlineOrNot itself paged me to say that something was wrong with the public API at 11:44 UTC. Clicking on the link in the alert showed me Cloudflare's typical error screen, with a key difference - my host was still working, Cloudflare was the one with the error.
As a means of working around it, I disabled DNS proxying in OnlineOrNot's Cloudflare DNS settings, and got access back to the frontend. I then noticed the API was still down.
In disabling DNS proxying, I discovered a bug in OnlineOrNot's frontend that relied on Cloudflare's proxying to function properly.
It would remain down until 15:41 UTC, when I was able to login to the Cloudflare dashboard again, and re-enable DNS proxying. Had I taken no action with the DNS settings, OnlineOrNot's dashboard would have been accessible at 14:33 UTC.
OnlineOrNot's uptime checking system
OnlineOrNot's uptime checking system is both multi-cloud and multi-region, running in AWS and Cloudflare Workers. Having learned our lesson from a large us-east-1 outage in 2021, the failover part of the system is frequently tested. Things still went wrong in new and different ways.
Each part of OnlineOrNot's Cloudflare system continuously reads config from KV, and writes health data to Workers Analytics Engine (WAE). There's also an autonomous Cloudflare Worker process that queries WAE every minute, and if the health of the system degrades, it updates the config in KV, and the system starts running on AWS.
During this incident, no part of this autonomous health system was functioning as expected, and I needed to manually trigger the CI process to redeploy the service to make it default to running in AWS. At 12:12 UTC, 28 minutes after noticing the disruption, OnlineOrNot was back up and running checks in AWS, and sending alerts.
These checks were however, less accurate than usual. The uptime checks in AWS relied on Cloudflare to double-check a URL is down. When the connection to Cloudflare was completely severed between 13:00 UTC and 14:33 UTC, the checks timed out in the queue, resulting in failing checks being skipped:
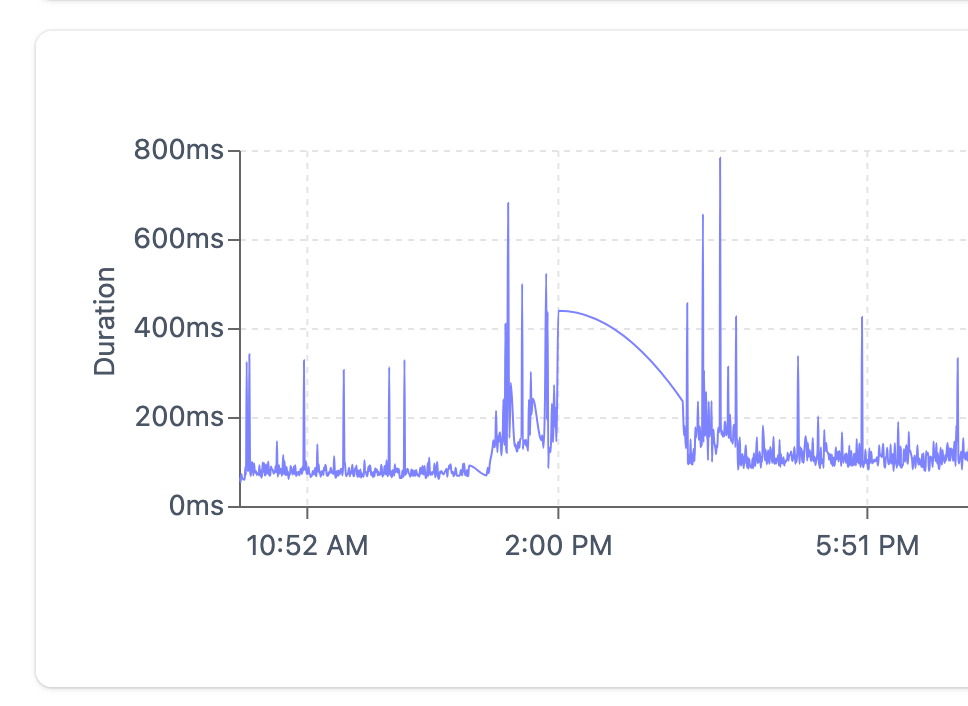
(This chart displays time in UTC+1)
OnlineOrNot's heartbeat (cron) monitoring system
OnlineOrNot's heartbeat system suffered similar issues to the uptime checking system. Heartbeats provide healthcheck URLs (also hosted on Cloudflare), which were unreachable between 13:00 UTC and 14:33 UTC.
The other side of the system that looks for heartbeats to alert on successfully ran from AWS thanks to the failover.
As a result, the heartbeat system started sending alerts for cron jobs that were still running.
OnlineOrNot's status pages
OnlineOrNot's status pages are powered by a Cloudflare Worker serving the frontend, and a Cloudflare Worker proxying the private API.
During the outage, status pages were completely inaccessible between 13:00 UTC and 14:33 UTC.
For customers experiencing their own incidents at the same time as the Cloudflare outage, they had no way to update their status pages or show their users what was happening.
Remediation steps
Now that the systems are back online and functioning normally, I have begun work to harden them against failures like this in the future. In particular:
- Adding multi-cloud fallback services to all APIs and frontends - one vendor is not enough for services like OnlineOrNot
- Eliminating the cross-cloud double checking on uptime checks in favor of same-region retries
- Implementing automatic DNS failover for status page domains to redirect to the fallback version during outages
- Reviewing and improving the autonomous health monitoring system that failed to trigger AWS failover automatically
An outage like this is unacceptable for a monitoring system like OnlineOrNot. I've architected our systems to be multi-cloud and resilient, but this incident exposed gaps in our failover automation and dependencies I hadn't fully accounted for.
I apologize for the disruption this caused to your monitoring and incident response yesterday.