Our lessons from the latest AWS us-east-1 outage

Max Rozen / Published: June 18, 2023
In case you missed it, AWS experienced an outage or "elevated error rates" on their AWS Lambda APIs in the us-east-1 region between 18:52 UTC and 20:15 UTC on June 13, 2023.
If this sounds familiar, it's because it's almost a replay of what happened on December 7, 2021, although that outage was significantly more severe and took longer to restore.
Table of contents
Some background on us-east-1
us-east-1 is the oldest and most used AWS region, it's where AWS EC2 was launched from in 2006. It has six availability zones (AZs), instead of the usual two or three.
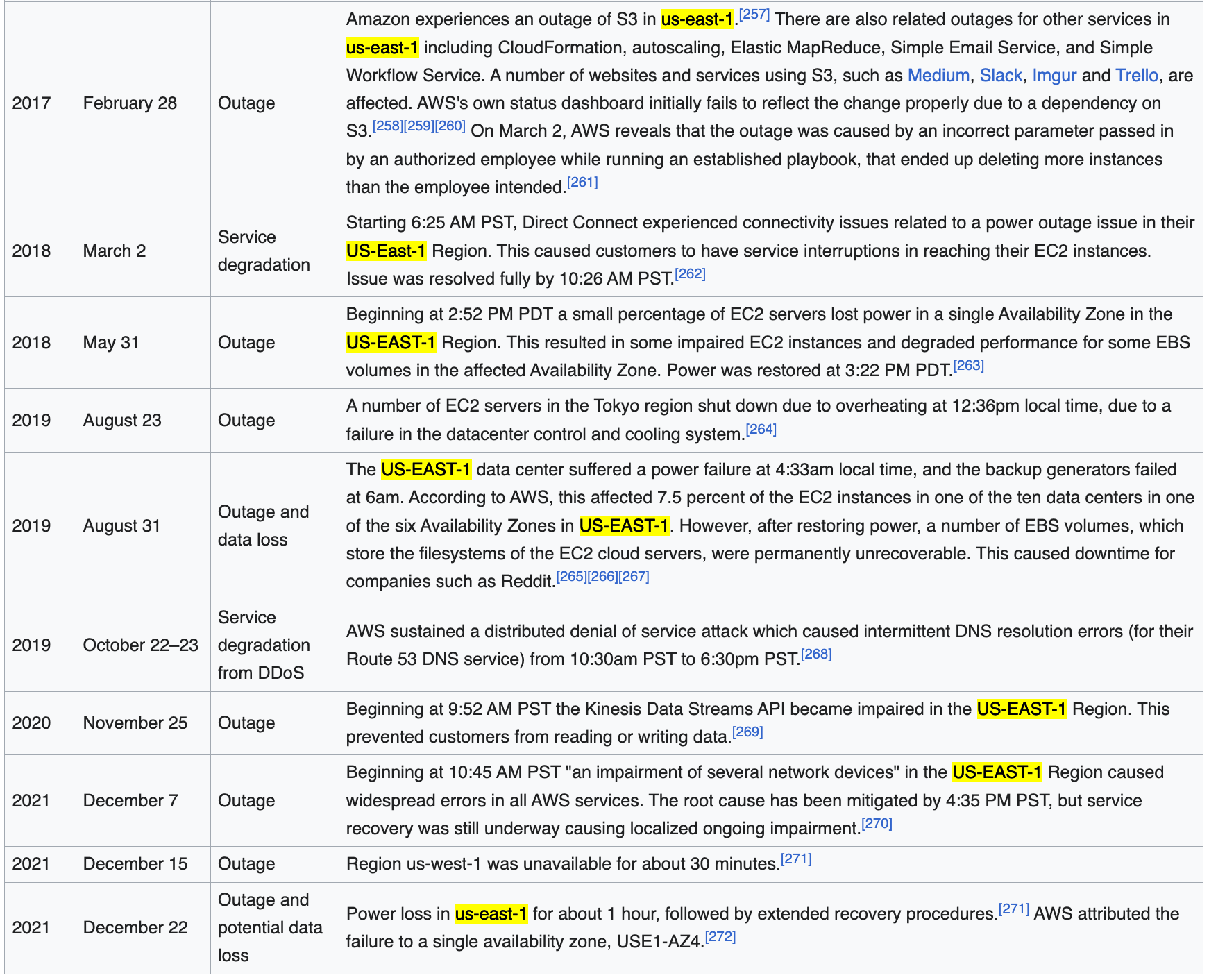
Bugs that show up under high load tend to show up there first. If you look at the list of AWS outages, you'll notice almost every major outage since 2017 started in us-east-1:
The easiest mitigation strategy
While folks may say us-east-1 is "just another region", you could avoid being impacted by major outages with one simple strategy:
Migrate to us-east-2.
It's not 100% foolproof, as some AWS services host their dashboard exclusively in us-east-1, so even if your service isn't impacted by an outage, you might not be able to check out the dashboard during an outage.
Unfortunately for OnlineOrNot, as an uptime monitoring service, things aren't that simple.
The retrospective
Some context
Since OnlineOrNot's job is to measure uptime, every service is designed to run across multiple AWS regions. There's a high availability API that OnlineOrNot's services use to figure out which region to run from, and I use that to dodge major outages (something I learned to build back in 2021).
What went wrong
A couple of weeks before the most recent AWS outage as part of an architecture refactor, I spun up a new alerting service in us-east-1, without taking the time to implement the same multi-region failover that OnlineOrNot's other systems use.
As a result, during the us-east-1 outage while uptime checks were successfully being scheduled, and running - the service that collects the results from individual checks was not.
What went well
The only redeeming part of this incident, was that it proved the failover system works.
After the outage, I took the time to add failover to the alerting service, and now the entire OnlineOrNot system has the ability to hop AWS regions.
What I learned
- Don't run production workloads on services that don't have failover implemented
- Regularly test service failover, end-to-end
- It's almost never a good idea to build things that run only in us-east-1